

This notebook contains an excerpt from the Python Programming and Numerical Methods - A Guide for Engineers and Scientists, the content is also available at Berkeley Python Numerical Methods.
The copyright of the book belongs to Elsevier. We also have this interactive book online for a better learning experience. The code is released under the MIT license. If you find this content useful, please consider supporting the work on Elsevier or Amazon!
< 16.4 Least Squares Regression in Python | Contents | 16.6 Summary and Problems >
Least Square Regression for Nonlinear Functions¶
A least squares regression requires that the estimation function be a linear combination of basis functions. There are some functions that cannot be put in this form, but where a least squares regression is still appropriate.
Introduced below are several ways to deal with nonlinear functions.
We can accomplish this by taking advantage of the properties of logarithms, and transform the non-linear function into a linear function
We can use the
curve_fitfunction fromscipyto estimate directly the parameters for the non-linear function using least square.
Log tricks for exponential functions¶
Assume you have a function in the form ˆy(x)=αeβx and data for x and y, and that you want to perform least squares regression to find α and β. Clearly, the previous set of basis functions (linear) would be inappropriate to describe ˆy(x); however, if we take the log of both sides, we get log(ˆy(x))=log(α)+βx. Now, say that ˜y(x)=log(ˆy(x)) and ˜α=log(α), then ˜y(x)=˜α+βx. Now, we can perform a least squares regression on the linearized expression to find ˜y(x),˜α, and β, and then recover α by using the expression α=e˜α.
For the example below, we will generate data using α=0.1 and β=0.3.
import numpy as np
from scipy import optimize
import matplotlib.pyplot as plt
plt.style.use('seaborn-poster')

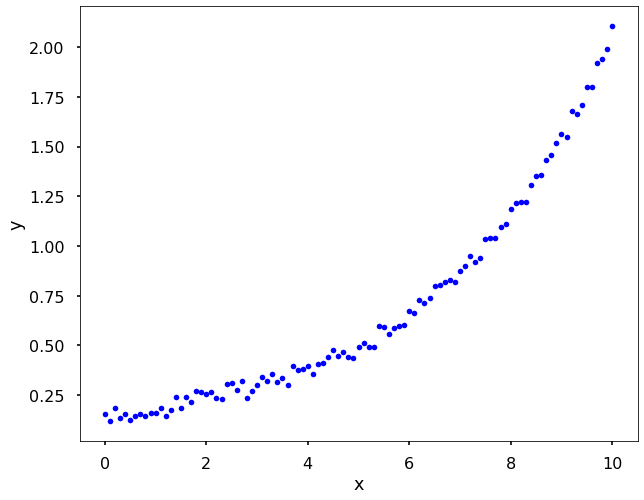
# let's generate x and y, and add some noise into y
x = np.linspace(0, 10, 101)
y = 0.1*np.exp(0.3*x) + 0.1*np.random.random(len(x))
# Let's have a look of the data
plt.figure(figsize = (10,8))
plt.plot(x, y, 'b.')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
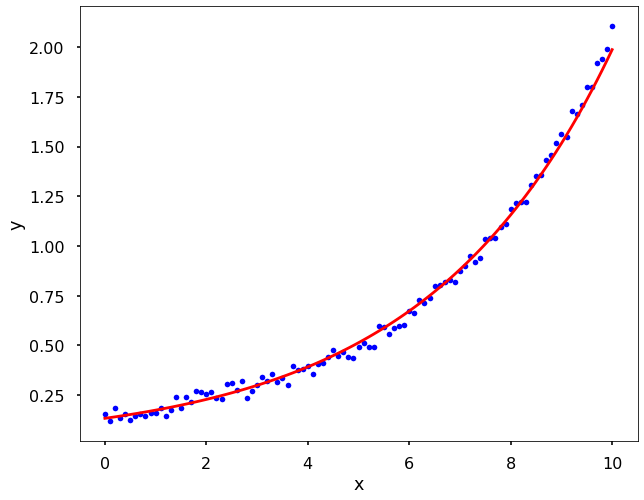
Let’s fit the data after we applied the log trick.
A = np.vstack([x, np.ones(len(x))]).T
beta, log_alpha = np.linalg.lstsq(A, np.log(y), rcond = None)[0]
alpha = np.exp(log_alpha)
print(f'alpha={alpha}, beta={beta}')
alpha=0.13233125271210974, beta=0.27092999595397904
# Let's have a look of the data
plt.figure(figsize = (10,8))
plt.plot(x, y, 'b.')
plt.plot(x, alpha*np.exp(beta*x), 'r')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
Log tricks for power functions¶
The power function case is very similar. Assume we have a function in the form ˆy(x)=bxm and data for x and y. Then we can turn this function into a linear form by taking log to both sides: log(ˆy(x))=mlog(x)+logb. Therefore, we can solve this function as a linear regression. Since it is very similar to the above example, we will not spend more time on this.
Polynomial regression¶
We can also use polynomial and least squares to fit a nonlinear function. Previously, we have our functions all in linear form, that is, y=ax+b. But polynomials are functions with the following form:
where an,an−1,⋯,a2,a1,a0 are the real number coefficients, and n, a nonnegative integer, is the order or degree of the polynomial. If we have a set of data points, we can use different order of polynomials to fit it. The coefficients of the polynomials can be estimated using the least squares method as before, that is, minimizing the error between the real data and the polynomial fitting results.
In Python, we can use numpy.polyfit to obtain the coefficients of different order polynomials with the least squares. With the coefficients, we then can use numpy.polyval to get specific values for the given coefficients. Let us see an example how to perform this in Python.
x_d = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8])
y_d = np.array([0, 0.8, 0.9, 0.1, -0.6, -0.8, -1, -0.9, -0.4])
plt.figure(figsize = (12, 8))
for i in range(1, 7):
# get the polynomial coefficients
y_est = np.polyfit(x_d, y_d, i)
plt.subplot(2,3,i)
plt.plot(x_d, y_d, 'o')
# evaluate the values for a polynomial
plt.plot(x_d, np.polyval(y_est, x_d))
plt.title(f'Polynomial order {i}')
plt.tight_layout()
plt.show()
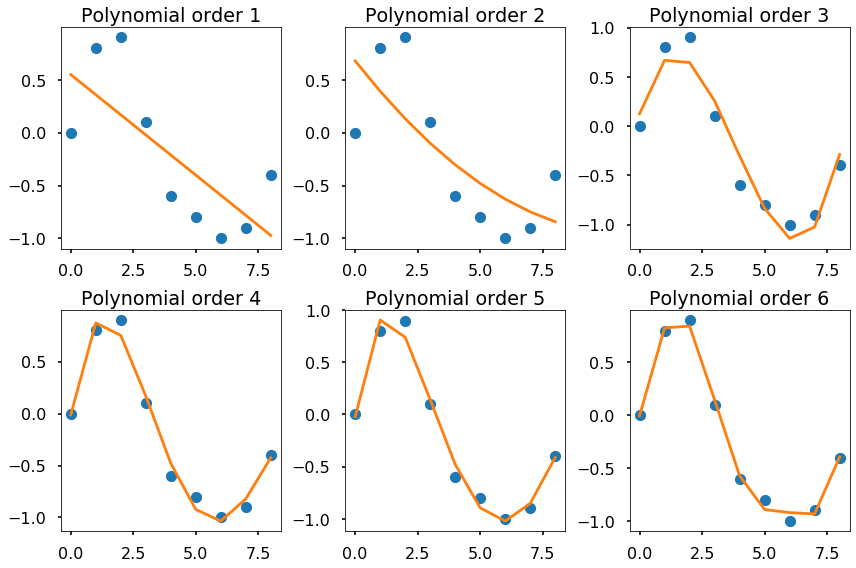
The figure above shows that we can use different order of polynomials to fit the same data. The higher the order, the curve we used to fit the data will be more flexible to fit the data. But what order to use is not a simple question, it depends on the specific problems in science and engineering.
Use optimize.curve_fit from scipy¶
We can use the curve_fit function to fit any form function and estimate the parameters of it. Here is how we solve the above problem in the log tricks section using the curve_fit function.
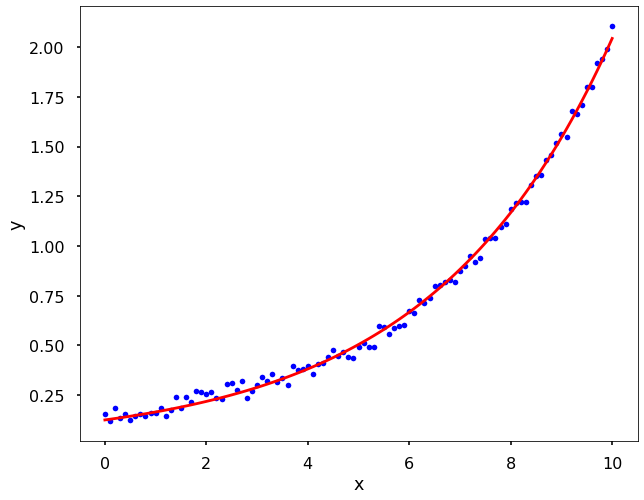
# let's define the function form
def func(x, a, b):
y = a*np.exp(b*x)
return y
alpha, beta = optimize.curve_fit(func, xdata = x, ydata = y)[0]
print(f'alpha={alpha}, beta={beta}')
alpha=0.12420824748558632, beta=0.28005793982974525
# Let's have a look of the data
plt.figure(figsize = (10,8))
plt.plot(x, y, 'b.')
plt.plot(x, alpha*np.exp(beta*x), 'r')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
< 16.4 Least Squares Regression in Python | Contents | 16.6 Summary and Problems >