

This notebook is an extension from the Python Programming and Numerical Methods - A Guide for Engineers and Scientists, the content is also available at Berkeley Python Numerical Methods.
The text is released under the CC-BY-NC-ND license, and code is released under the MIT license. If you find this content useful, please consider supporting the work on Elsevier or Amazon!
< CHAPTER 25. Introduction to Machine Learning | Contents | 25.2 Classification >
Concept of Machine Learning¶
Machine learning, as the name suggest, are a group of algorithms that try to enable the learning capability of the computers, so that they can learn from the data or past experiences. The idea is that, as a kid, we gain many skills from learning. One example is that we learned how to recognize cats and dogs from a few cases that our parents showed to us. We may just see a few cats and dogs pictures, and next time on the street when we see a cat, even though it may be different from the pictures we saw, we know it is a cat. This ability to learn from the data that presented to us and later can be used to generalize to recognize new data is one of the things we want to teach our computers to do.
Machine learning algorithms are used in many places in our life that you may not realize it. For example, your voice assistant on your smartphone, the ATM machine recognize the deposit checks, your email provider automatically separate the good emails from the junk ones, the self-driving cars drive without a driver, facial recognition at some of the security checks, and many more examples. Therefore, in this chapter, we will introduce you some of the basic concepts of machine learning as a way to motivate you to learn more beyond this book. Let’s first start to see what makes of a machine learning algorithm.
Types of machine learning¶
There are different types of machine learning algorithms. One popular way to classify them is shown in the following figure:
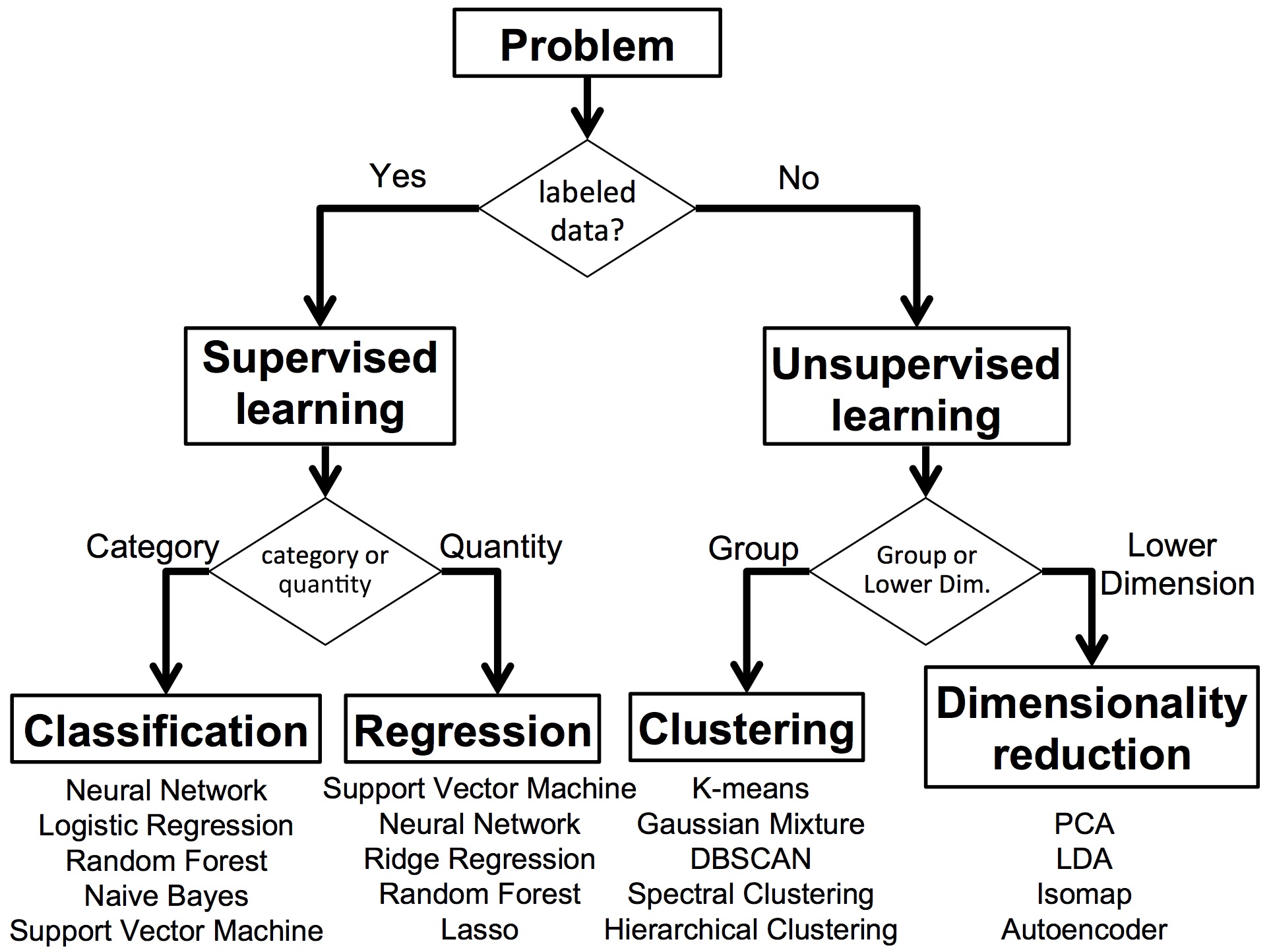
Usually, we classify machine learning into two main categories, i.e. supervised learning and unsupervised learning. The supervised learning as the name suggested, is that during the training of the algorithm, we know the correct label, which means we know the answers of the problem, this prior information will be used in the training. Within the supervised learning, depending on the nature of the output, we can divide the algorithms into classification and regression. For example, if we are asked to design an algorithm to recognize apple and oranges, and we know which object is apple or orange, then this problem is the classification problem, since the output will be categorical data, either orange or apple. The different objects are usually called classes. The fact that we know the apple or orange makes it into a supervised learning. In another example, if we want to predict your final exam scores (0 - 100) based on your each homework score, the output is a quantity from 0 to 100, then this is a regression problem. The other category of the algorithms are unsupervised learning, which means we don’t have the luxury of the labels. For example, if I give you a mixed apple and oranges, but don’t tell you which one is apple, which one is orange. Then this will be a clustering problem, which you need to use some of the hidden characteristics of the objects to group them together. Dimensionality reduction is a group of algorithms within the category of unsupervised learning to reduce the higher dimension problems into lower dimension ones. As a human being, we like to work in lower dimensions, for example, our world is a 3-dimensional environment, and people reduce it to 2-dimension to plot it on the map for easier visualizations. Algorithms are the same, sometimes it is easier to work in the lower dimensions to make things easier, therefore, the algorithms that can reduce the dimensionality will be useful in these cases.
Of course, there are many more other types of machine learning, such as reinforcement learning, we will not talk about it here. The above types are the most common ones, in this chapter, we will give you a brief tour of classification, regression and clustering and show you how to quickly do it in Python using one package.
The components of machine learning¶
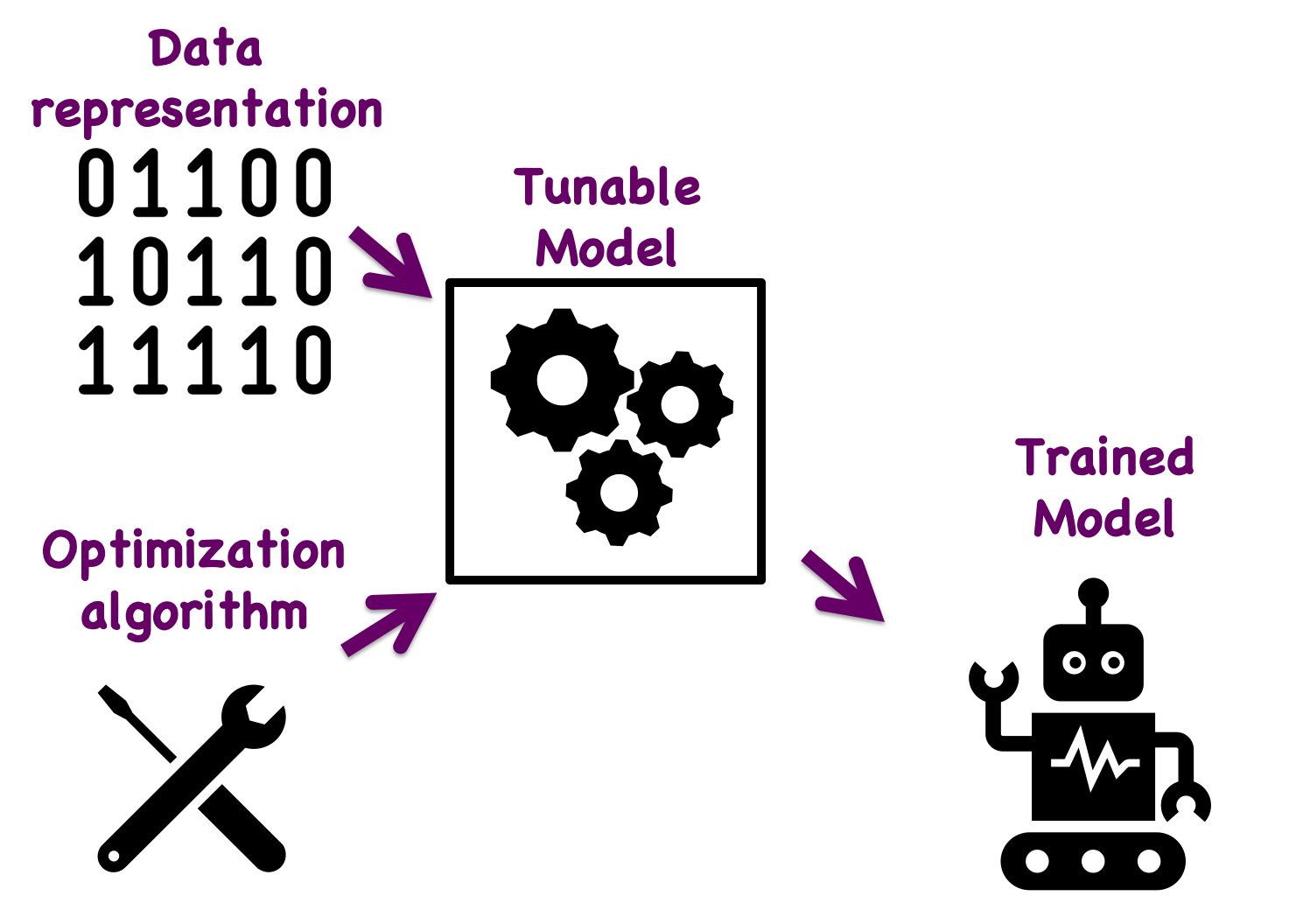
The above figure shows the main components of a machine learning algorithm:
representation of the data
a tunable model
optimization algorithm to tune the model
a trained model
Representation of the data
There are many types of data, such as images, time series, text documents, numerical data, and so on, we need to turn the data into some format that the computers can recognize it. For example, one way we can do to represent data for machine learning is shown as following figure:
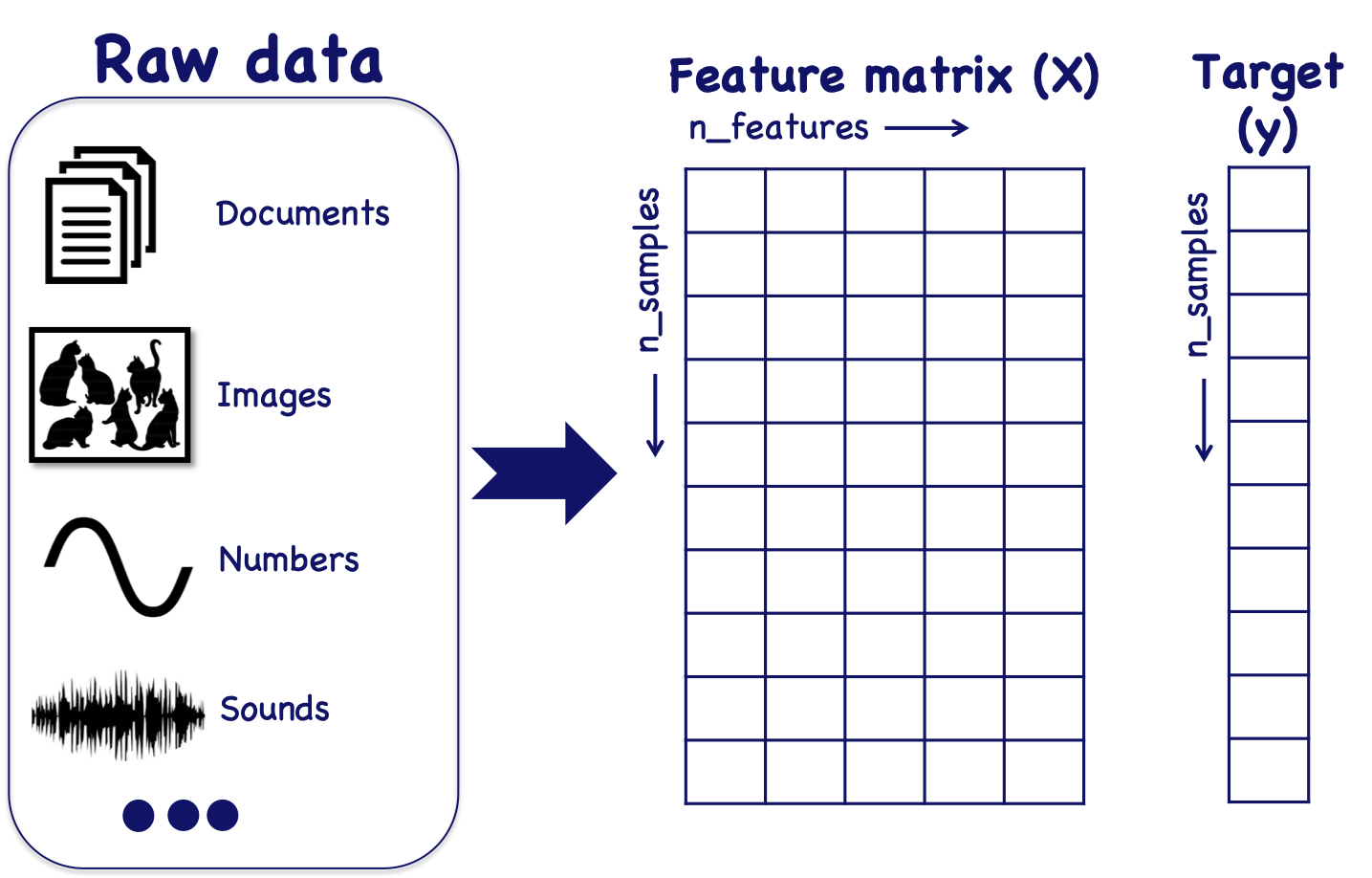
We can see that we usually represent the input data into a matrix, with each row represent one sample of the data (or instance of data). For example, if we have a problem to recognize apples and oranges, then each row can store one apple or one orange. The columns are different features, usually characterize the different objects, in this case, it can be color, texture, shape, smell and so on of the objects. This matrix is usually called feature matrix which represent our data in a way that can feed into the computer. We will also have a target array, which stores the output of the values. Either it will be the label of the different classes, or the quantities. There are also other representations of the data, for example, the data is still stored in an array, but each row is saving a 2D array for an image.
Tunable model After we have the input and output data ready, we need an algorithm that can learn from the data. The algorithms are usually have many different parameters that can be tuned in a way that the model can become better for our goal based on the data we present to it. There are many different tunable models such as artificial neural network support vector machine, random forest, logistic regression, and so on. Each model has different ideas behind it and be tuned differently.
Optimization algorithm This is the main working force behind the machine learning algorithms. We need to tune the model, but how? Usually we need to define some sort of objective function and use the optimization algorithms to either minimize or maximize it. The objective function could be calculated by the difference/error between the estimation and the target (true answer), therefore, usually the smaller the error is, the better. There are different optimization algorithms to tune the model, such as gradient descent, least square minimization, and so on.
Trained model After the tuning of the model, it has the capability of making a classification or prediction and so on. This trained model can be used on the new data for achieving our goal.
< CHAPTER 25. Introduction to Machine Learning | Contents | 25.2 Classification >